Machine learning pode revelar engrenagens da mente

O cientista da computação Sanjeev Arora acredita que os algoritmos mais eficientes de descoberta de padrões em dados não estruturados podem ajudar a descobrir como a mente funciona. Em sua plenária nesta terça-feira (7), ele disse que as técnicas de machine learning abrem espaço para “um novo tipo de ciência”.
Esses algoritmos aprendem a partir da experiência e interação com os dados. Quanto maior o volume de dados, mais padrões eles descobrem. Com isso, imitam a forma como a inteligência humana funciona, de maneira cada vez mais sofisticada. Para ele, o uso de machine learning pode ajudar a revelar como funcionam aspectos desconhecidos de como funciona a mente.
Leia também: Noite de música e dança no jantar social do ICM 2018
Matemática e Ciência da Computação interligadas
Nalini Anantharaman fala sobre sistemas ergódicos
Se antigamente era necessário ensinar as regras da gramática a um algoritmo que traduz textos, a crescente disponibilidade de dados digitais para análise e capacidade de processamento permitem que os algoritmos descubram os elementos que estão ligados entre si usando previsões feitas a partir da frequência com que, por exemplo, uma palavra aparece depois da outra num conjunto grande de textos. De certa forma, isso se assemelha à maneira como bebês aprendem a falar.
O exemplo que Arora utilizou para demonstrar a Matemática do aprendizado de máquinas foi o de como saber, a partir do vocabulário, se uma resenha de filme disponível na Amazon é positiva ou negativa, prevendo a avaliação numérica para criar uma espécie de “lei das avaliações de resenhas de filme”.
A frequência das palavras em avaliações positivas e negativas permite calcular uma correlação de cada palavra com cada “sentimento” envolvido na análise. É difícil fazer isso por meio de computação, mas a mente humana já o faz instintivamente. “Na primeira resenha que você lê, você já sabe qual é o sentimento”, diz.
Os algoritmos, porém, compreendem o resultado apenas passivamente, pois não existe modelo matemático da linguagem.
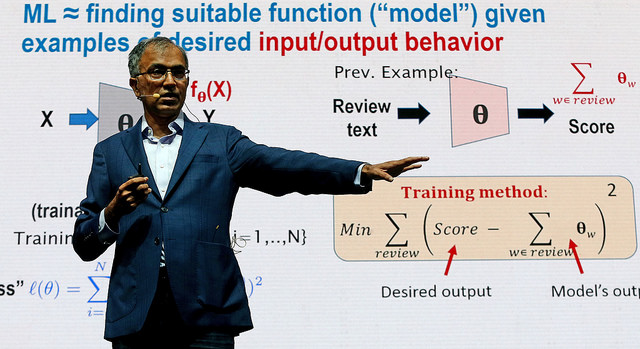
Na aplicação de machine learning a um conjunto de dados complexos como a linguagem natural, é preciso criar e otimizar uma função de perda a partir de um conjunto de teste (geralmente com 80% dos seus dados) e testar o quanto ele é eficaz com novos dados (geralmente os 20% remanescentes) antes de ter um algoritmo que se aplique ao mundo em geral.
A redução da perda nos dados de treino se dá por meio do método do gradiente, que busca os mínimos de uma função. A cada passo, ele melhora os dados. Por meio da propagação reversa (backpropagation), gera-se um resultado “não-linear o suficiente para expressar muitas coisas, mas linear o bastante para ser computável”.
Em parte dos casos, usa-se aprendizado não-supervisionado, onde o computador calcula sozinho as probabilidades envolvidas no corpo de dados utilizado. Trata-se de um algoritmo de “caixa preta”, de difícil detalhamento do processo de decisão, sem transparência sobre quais as variáveis pesam na previsão. Um dos temas de investigação de Arora é a análise de caixas-pretas, por meio de pequenos passos.
Sua apresentação completa pode ser baixada neste link. Aos interessados no tema, Arora recomenda que assistam à plenária de Michael Jordan, no dia 8 (quarta).